

How to reduce sovereignty risk in the context of AI models?
It’s been clear for several months now that Europe cannot rely on the US alone in a number of critical areas — defence and technology foremost among them. Across many industries, companies are now considering how to reduce dependency not only on the US, but also on any partners they no longer regard as their closest allies. In this political environment, it was only a matter of time when frontier AI models would become politicised.
Still, few expected Anthropic to end up at the centre of this battle — first by refusing the US government free use of its models, and then by shutting down access to its most powerful model, reportedly at the direction of the US government.
This raises a broader question: to what extent can European companies rely on non-European LLM providers, especially as they move agentic proof-of-concepts into production (a very hot topic at the moment)? Even setting aside the inherent risk of running production solutions on models whose infrastructure is outside our control (i.e., via an external provider’s API), “model sovereignty” risk is, in practice, a vendor lock-in problem.
A company is locked in to a vendor when it cannot replace that vendor without significantly disrupting operations — or can do so only at a cost so high that it outweighs the benefits of using an external provider that offers better pricing and/or higher-quality services.
Vendor lock-in for AI solutions: where it exists (and where it does not)
The paradox of AI solutions is that the large language model itself is very expensive to build and run, yet relatively easy to switch from the consumer’s perspective. Competition is intense, with several providers racing for building the best solution (with Anthropic being the current leader).
By contrast, the layer built on top of the LLM — the so-called harness — is far cheaper and easier to develop, yet it is often what makes switching providers difficult. Let me explain.
A “pure” LLM is, essentially, a machine for reading and writing text (and code). You ask a question; it responds. On its own, it cannot execute the code it writes. It cannot open, search, or modify files. Today’s chatbots can do these things precisely because they are connected to programmatic tools that allow them to act. That surrounding toolset and orchestration is what is meant by the “harness”, which may include:
Functions that can search files, read file contents, and modify files,
Functions that perform calculations, e.g. financial valuation and risk metrics (a frequent use case on this blog and within our company),
Access to the internet,
Connectors to other applications that allow to book a hotel, open a Jira ticket, or update a GitHub repository,
“Memory”, accumulated across conversations, allowing the system to learn a user’s context, preferences, and recurring needs,
Additional capabilities, such as manipulating spreadsheets and slide decks.
When you use ChatGPT.com or Claude.ai, the LLM and the harness appear to be one single thing. Internally, they are two distinct components.
The harness is a set of programmed functions. It contains no AI itself — and in many organisations, elements of that harness existed long before the current wave of agentic AI (e.g. pricing models for financial instruments, or risk indicators computing engines).
So when we say, “an LLM can value a financial instrument”, what actually happens is more like:
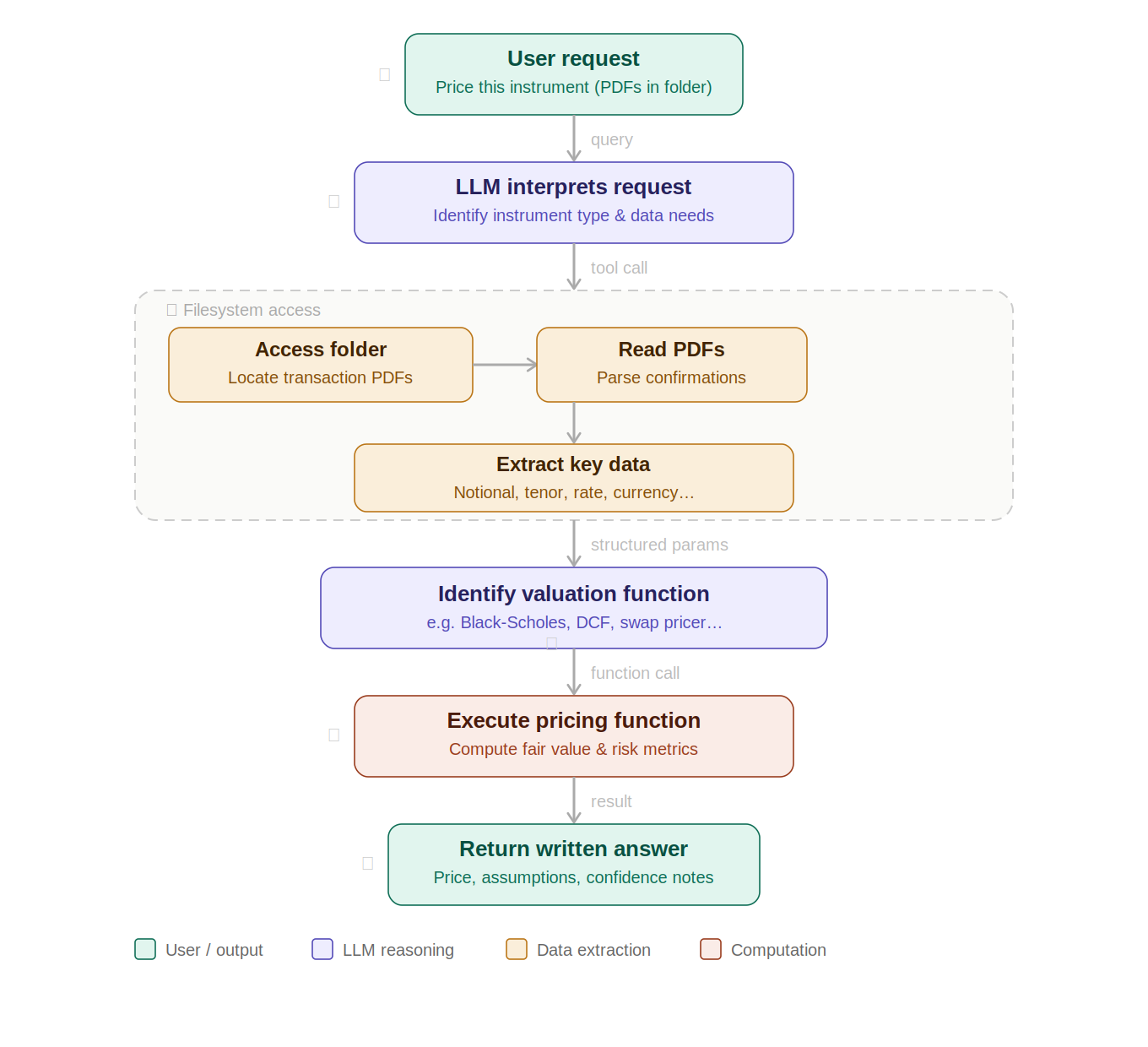
And that brings me to the core point of this article: you can either let the model provider manage all parts of this process, or you can consume only the model and build (and own) everything around it — the harness — yourself.
Building your own frontier model is extraordinarily expensive. Building the harness is comparatively straightforward (especially today, when AI can materially accelerate the coding work). If you own the harness, you can switch models with something close to a “button press” if you find a cheaper, more efficient, higher-quality provider — or if a provider withdraws its service.
If, however, you outsource the harness and allow the provider to learn deep details about your business (including the full business logic of your processes), switching AI vendors later becomes far more difficult and costly.
I’m building my own harness - how powerful the LLM needs to be?
The schema above depicts a very simple example; real corporate workflows are often far more complex. But it is enough to imagine two broad approaches:
LLM as the “brain”: the model decides the overall course of action upfront and effectively designs the workflow on the fly,
Deterministic orchestration: a human (or a set of deterministic functions) defines the sequence of steps, and the LLMs perform selected tasks within that sequence — without being responsible for the orchestration.
As the complexity of the process increases, the first approach will tend to require the most capable (and therefore most expensive) models. The second approach can often be served by less powerful models — and, with reasonable testing, by the least-powerful-model-able-to-do-the job.
Whether you truly need the most capable models, or can use smaller ones for a given business process, is a deeper topic. I’ll write more about it in the next article.
For more technical readers, I recommend this excellent recent entry on model neutrality by LangChain: https://www.langchain.com/blog/model-neutrality